기술·제품
기술·제품
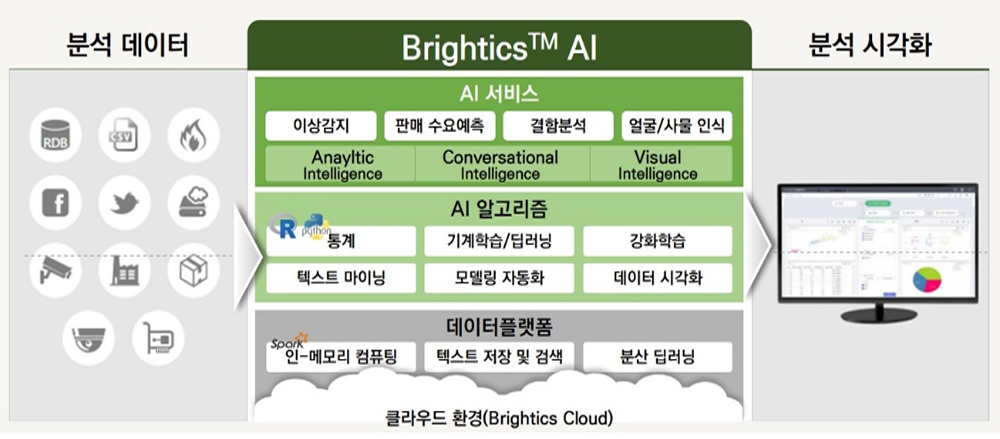
Brightics AI
분산된 데이터를 자동화 처리 기능을 통해
직관적으로 수집하고 관리할 수 있는 빅데이터 통합 플랫폼입니다.
Brightics AI 강점
Ingest Accelerator 기능 이용으로 데이터 고속 수집 서비스
다양한 데이터 유형 및 데이터소스로부터 데이터 수집 가능
데이터 가상화를 통한 데이터 수집 전, 탐색/변환 가능
실시간 데이터 처리 및 분석 가능
Auto Schema Builder로 Data 파싱 자동화 지원 가능
Visual Query를 통해 데이터 처리가 쉽고 편리한 서비스
주요기능
시각화된 통합 분석 환경 제공
Pre-Built/사용자정의 ML 함수 지원
정형/비정형 분석 기능
자동 변수/분석 알고리즘 추천
Script Modeling(R, Python, SQL, Scalar)
분석 리포트 자동생성 및 배포(웹/모바일 지원)
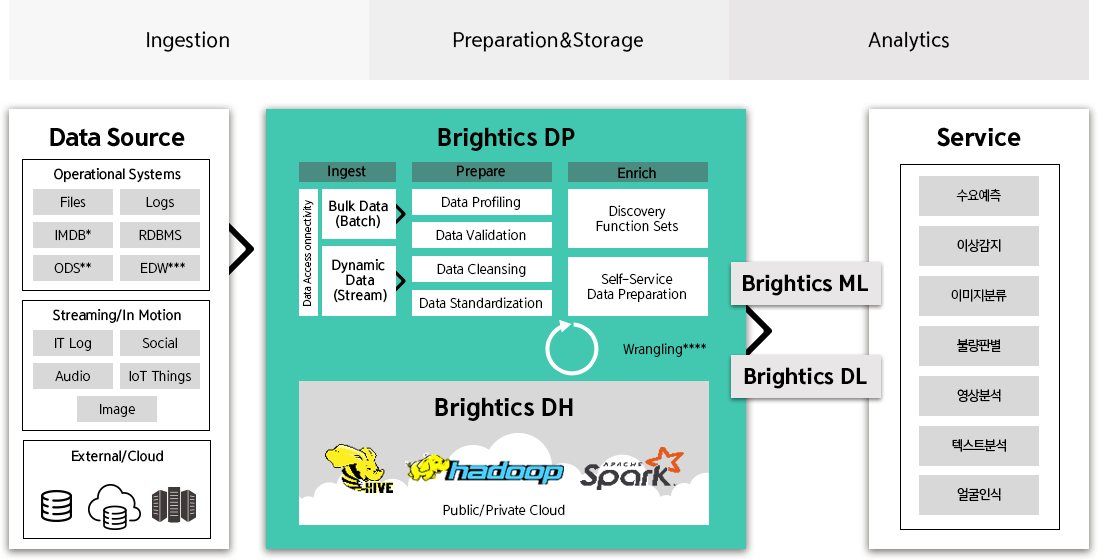
Brightics AI 구성도
Brightics AI는 다양한 데이터소스로부터
데이터를 수집(Ingest), 정제(Prepare), 보강(Enrich)하는
ETL/ELT 솔루션으로 Brightics DH(저장)∙ML(분석)
∙DL(분석)와 함께 Brightics AI 빅데이터 플랫폼을
형성하고 있습니다.
* IMDB : 영화, 배우, 텔레비전 드라마, 비디오 게임 등에 관한 정보를 제공하는
온라인 데이터베이스
** ODS(Operational Data Store) : ODS는 데이터에 대한 추가 작업을 위해 다양한 데이터 원천(Source)들로부터 데이터를 추출 및 통합한 데이터베이스
*** EDW(Enterprise Data Warehouse) : ODS를 거쳐 운영 데이터베이스(Operational Database) 및
외부 데이터 Source로부터 필요 데이터를 추출하여,
경영분석/의사결정의 지원을 위해 최적화된 구조로 변환된 데이터베이스
**** Wrangling : 분석과 같은 다운스트림** 목적에 적합하고 가치 있게 만들기 위해 하나의 원시 데이터(raw data)에서 다른 형식으로 데이터를 변환하고 매핑하는 과정
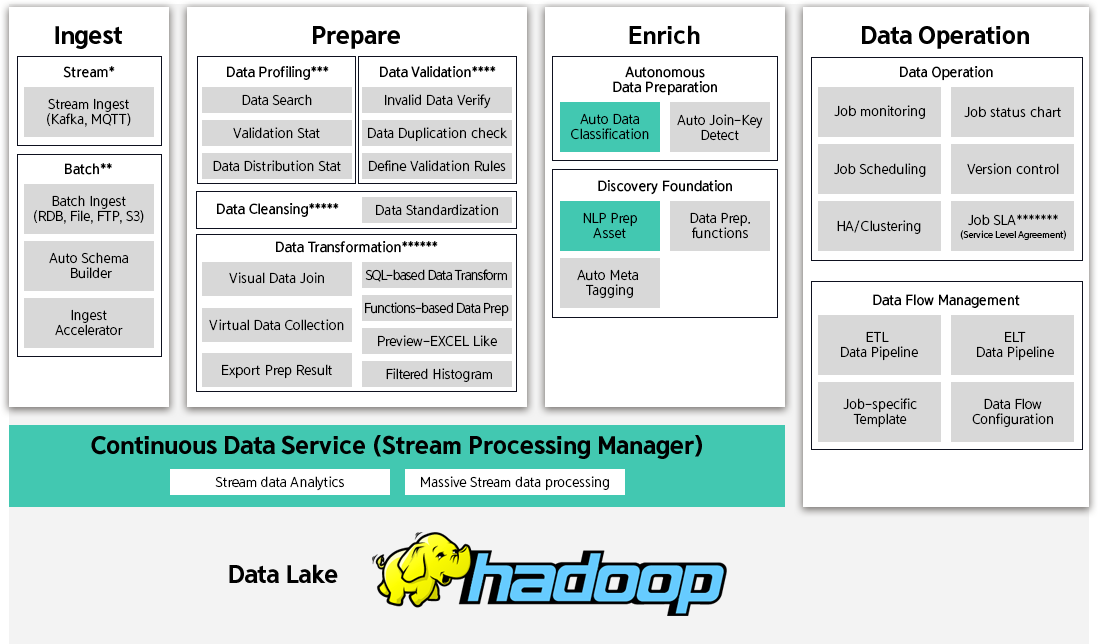
Brightics DP
(Data Preparation)
Architecture
Brightics DP의 아키텍처는 크게 Stream/Batch 방식으로
데이터를 수집하는 Ingest, 정제하는 Prepare,
데이터 병합을 통해
데이터를 보강하는 Enrich,
Ingest/Prepare/Enrich에 해당하는 Job을 관리하는
Data Operation으로 구성됩니다.
* Stream : ‘흐르다’ 또는 ‘개울’이라는 사전적 의미로, 동영상 시청 또는 음악 감상 등을 위해 서비스할 데이터를 실시간으로 처리하는 기술
** Batch : ‘(일괄적으로 처리되는) 집단’이라는 사전적 의미로, 데이터를 축적하여 일정한 주기마다 축적된 데이터를 하나로 종합하여 처리하는 데이터 처리 기술
*** Data Profiling : 데이터 소스에서 사용할 수 있는 데이터를 탐색하고 해당 데이터에 대한 통계 또는 유익한 요약을 수집 하는 프로세스
**** Data Validation : 데이터를 수집하는 과정에서 사전에 설정한 검증 규칙에 적합한 유효한 데이터가 들어왔는지 검증하는 프로세스
***** Data Cleansing : 원천 데이터 혹은 통합된 원천 데이터의 포맷을 통일하거나, 누락값을 제거하거나, 구분자 (delimiter) 를 입력하거나,
데이터의 불필요한 값을 제거하는 등의 작업을 통해 고품질 데이터의 요건을 갖추는 작업
****** Data Transformation : 여러 데이터를 병합하거나 DP에서 제공하는 Spark Function을 활용하여 데이터를 사용하고자 하는 형식으로 변환하는 프로세스
******* SLA (Service Level Agreement) : 서비스 운영 측면에서 고객의 요구사항을 충족하는 서비스 수준을 정의한 협약이며,
서비스 수준에 대한 측정지표로는 CPU 가용시간, CPU 응답시간, 헬프 데스크 응답시간, 서비스 완료시간 등이 있음
Brightics DP(Data Preparation) 구성요소
Brightics DP는 Ingest, Prepare, Enrich, Data Operation의 구성요소별 설명은 다음과 같습니다.
| 구성요소 | 설명 | ||
| Ingest | Stream | Ingest | Kafka 또는 MQTT 기반 Stream Data Source로부터 실시간 데이터 수집 |
| Batch | Ingest | Job Scheduling 기능을 활용한 RDB, File Directory, S3 등 Batch Data Source로부터 주기적인 데이터 수집 |
|
| Auto Schema Builder | 텍스트 기반 반정형 데이터를 파싱하여 자동으로 정형 데이터로 변환 | ||
| Ingest Accelerator | 대용량, 대규모 테이블 고속 수집 및 조건에 맞는 맞춤형 데이터 수집 | ||
| Prepare | Data Cleansing | Data Standardization | K-Means, Minhash-LSH, String Edit Distance, Metaphone 알고리즘을 활용하여 유사한 데이터를 그룹화 |
| Data Profiling | Data Search | Category, Feed, Table 별로 시스템명/설명/태그를 지정하여 raw 데이터 또는 수집 및 정제한 데이터의 원활한 검색 기능 제공 |
|
| Validation Stat. | Validation Rule을 적용한 데이터를 valid/invalid로 구분하여 Feed가 실행되면서 생성되는 데이터에 대한 이력, 통계 등 조회 기능 제공 |
||
| Data Distribution Stat. | Feed가 실행되면서 생성되는 데이터에 대한 통계량(최댓값/최솟값/평균/표준편차/분산 등)을 조회하는 기능 제공 | ||
| Data Validation |
Invalid Data Verify | 설정한 Validation Rules에 따라 수집된 데이터의 유효성 검사 실시 | |
| Data Duplication check | Feed가 실행되면서 생성되는 데이터의 각 컬럼별 중복 여부를 체크하여 불필요한 데이터 중복여부 방지 |
||
| Define Validation Rules | 데이터 표준화 기준을 설정하거나 신용카드 번호/날짜 포맷/이메일 등 검증 규칙을 설정하여 데이터 유효성 검증 |
||
| Data Transformation |
Visual Data Join | 시각화된 환경에서 여러 테이블을 병합 | |
| Virtual Data Collection | 원격지에 있는 데이터를 로컬 데이터처럼 메타데이터로 등록하고, End User의 데이터 조작 시 On-Demand로 데이터를 미리 탐색, 병합, 가공해서 미리보기를 제공 |
||
| Export Prep Result | 정제된 데이터를 Target System(Local Directory, HDFS 등)으로 저장 | ||
| SQL-based Data Transform |
Data Source로부터 불러온 테이블들을 SQL 쿼리문을 활용하여 정제 및 변환 | ||
| Functions-based Data Prep. |
DP에서 기본적으로 제공하는 Spark 기반 Function 또는 커스터마이징한 Function을 활용하여 데이터 가공 및 정제 |
||
| Preview- Excel Like | DP를 통해 수집, 정제한 데이터를 엑셀 UI 형태로 시각화 기능 제공 | ||
| Filtered Histogram | 각 컬럼별 Value 및 해당 Value별 건수를 파악하고 특정 Value를 제거하는 Filtering 기능 제공 | ||
| Enrich | Autonomous Data Preperation |
Auto Data Classification | 추가 예정 |
| Auto Join-Key Detect | 하나의 데이터의 string 또는 int 타입의 컬럼에 대해 Join 가능한 컬럼을 가진 다른 데이터를 자동으로 추천 |
||
| Discovery Foundation |
NLP Prep Asset | 추가 예정 | |
| Data Prep functions | 데이터 변환 시 활용가능한 Spark 기반 Function | ||
| Auto Meta Tagging | 데이터셋의 메타 정보를 자동으로 추출하여 태깅 | ||
| Data Operation |
Data Operation |
Job Monitoring | Job Scheduling에 등록된 Job의 진행 상태를 Running/Failed/Complete/Abandoned로 구분하여 모니터링 |
| Job status chart | Job의 진행현황을 Table/TableBarchart/Heatmap/Line Chart/Bar Chart/Area Chart/ Scatter Chart로 시각화 |
||
| Job Scheduling | 데이터를 수집, 가공 및 정제 또는 병합하는 하나의 Feed를 하는 하나의 Job으로 예약하여 정해진 시간마다 주기적으로 수행 |
||
| Version control | Job을 버전 관리 | ||
| HA/Clustering | Active-Active Clustering 서버 이중화 구조를 통해 High Availability 및 Scalability, Zero Downtime에 가까운 성능 제공 |
||
| Job SLA | 사전에 작성된 SLA 측정지표(서비스 가동률/동일장애 발생률/장애 및 오류 건수 등)에 따라 Job의 서비스수준 운영관리 |
||
| Data Flow Management |
ETL Data Pipeline | 데이터를 추출 및 가공, 정제하여 미리 설계된 DW에 적재하는 프로세스를 관리 | |
| ELT Data Pipeline | 데이터를 추출하여 Data Lake에 적재하고 필요 시 변환하여 사용하는 프로세스를 관리 | ||
| Job-specific Template | 기본 템플릿인 Data Ingest, Multi Table Ingest, Data Transformation Template을 활용하여 Job에 특화된 Template을 개발 |
||
| Data Flow Configuration | 추가 예정 | ||
| 공통 | Continuous Data Service |
Stream data Analytics | 활성화된 Stream Job의 평균 배치 처리 시간/초당 입력된 레코드 수/총 실행 시간/ 할당 메모리 등을 시각화하여 모니터링 |
| Massive Stream data processing |
Multi Table Ingest 템플릿을 활용하여 대용량 스트림 데이터를 수집 및 정제 | ||
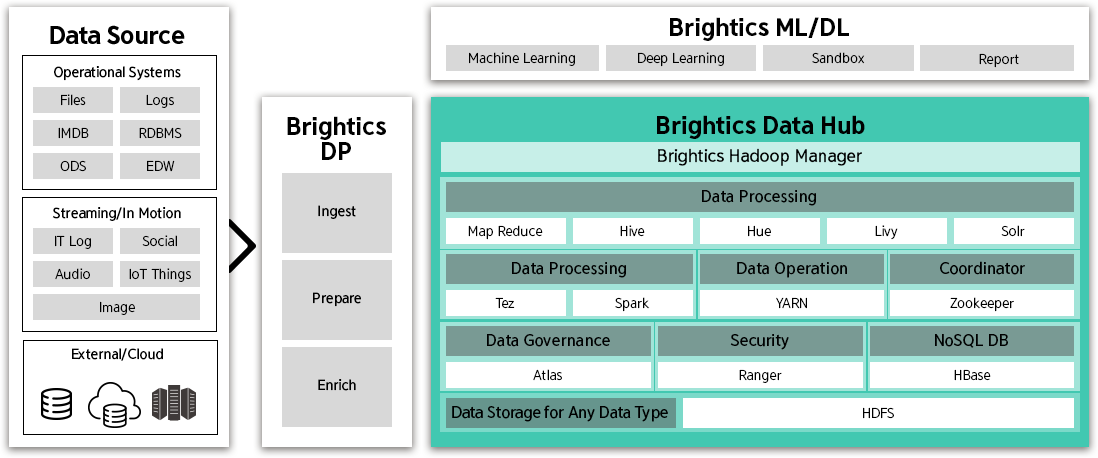
Brightics DH(Data Hub)
Architecture
Brightics DH의 아키텍처는 Hadoop 에코시스템의
주요 컴포넌트들을 Management 기능과
Web UI 기반의 패키징하여 제공하는 데이터 저장 플랫폼으로,
데이터를 효율적으로 관리할 수 있는 컴포넌트를 구성하고
Brightics Data Hub Manager를 제공합니다.
Brightics ML
(Machine Learning)
Position
Brightics ML은 분석 모델을 만들고 배포하기 위한
데이터 정제, 모델 개발, Deploy 및 App 개발
기능을 수행합니다.
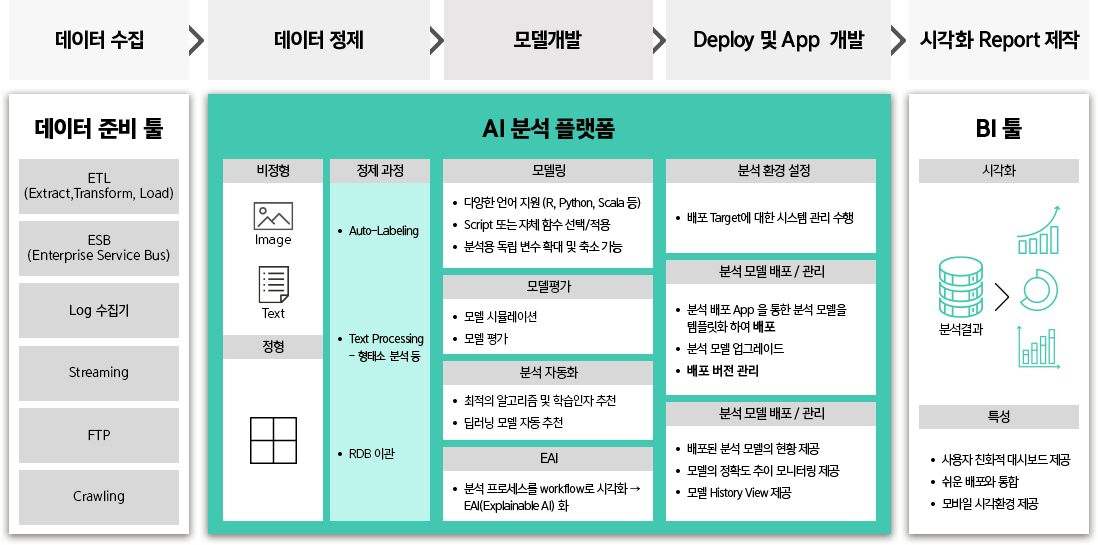
Brightics ML
(Machine Learning)
Architecture
Brightics ML의 아키텍처는 Brightics Server,
Brightics DL Agent의 구성은 아래와 같습니다.
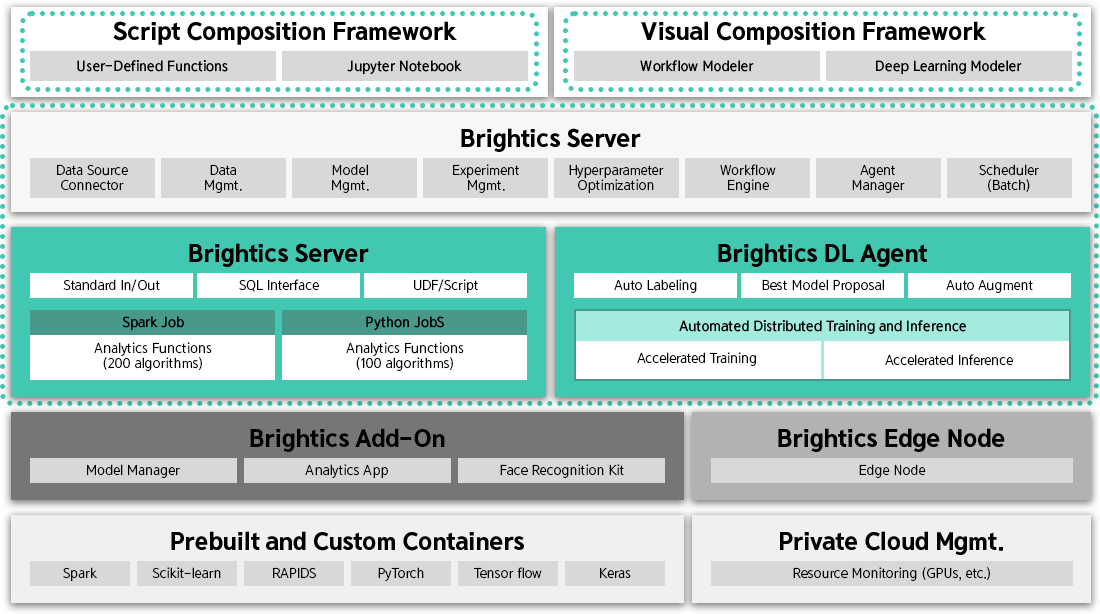
Brightics ML
(Machine Learning)
핵심요소
Brightics ML은 데이터 수집부터 운영까지
Machine Learning 모델의 전체 Life Cycle을 관리하는
E2E 분석 플랫폼을 제공하고,
Professional DS도 자유롭게 분석 및 모델 개발을
진행할 수 있도록 개인화된 Sandbox 환경을 제공합니다.
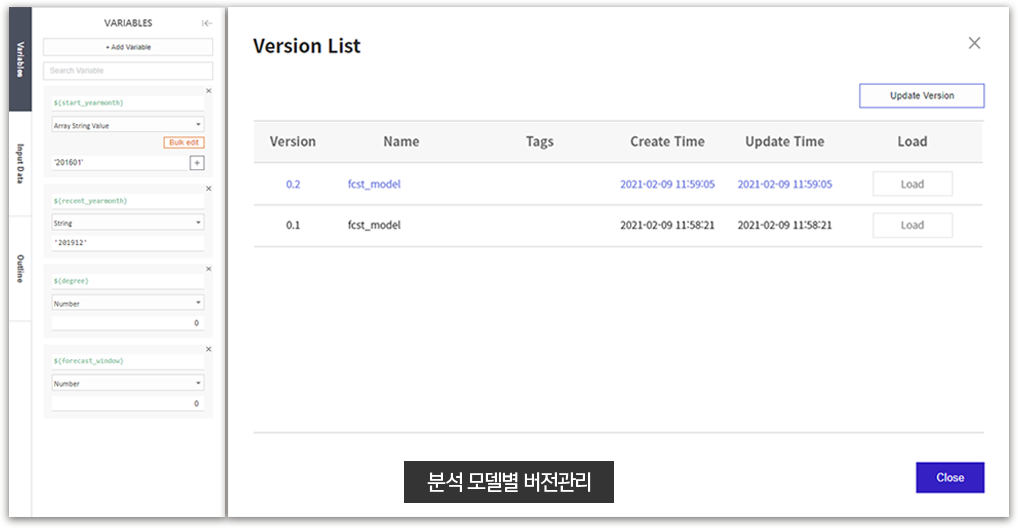
모델 버전 및 변수 관리
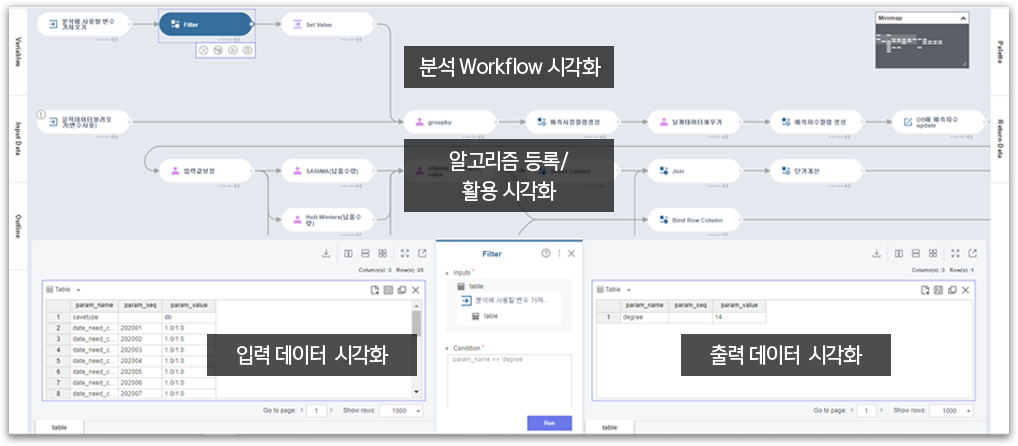
시각화된 작업환경
분석 자동화
Report 및 스케줄관리
배포 관리

Brightics ML
(Machine Learning)
구성요소
Brightics ML의 모델 버전, 변수관리, 시각화, 분석 자동화,
Report 및 스케줄 관리, 배포 관리의
구성요소별 설명은 다음과 같습니다.
| 구성요소 | 설명 |
| 모델 버전 및 변수 관리 |
Version List를 통해 분석 모델의 버전을 관리하고 Variables Tab을 통하여 모델에 사용된 변수 관리 기능 |
| 시각화된 작업환경 |
시각화된 작업환경은 모델 분석 과정, 입출력 데이터 등의 분석 프로세스를 시각화하여 기능 제공 |
| 분석 자동화 |
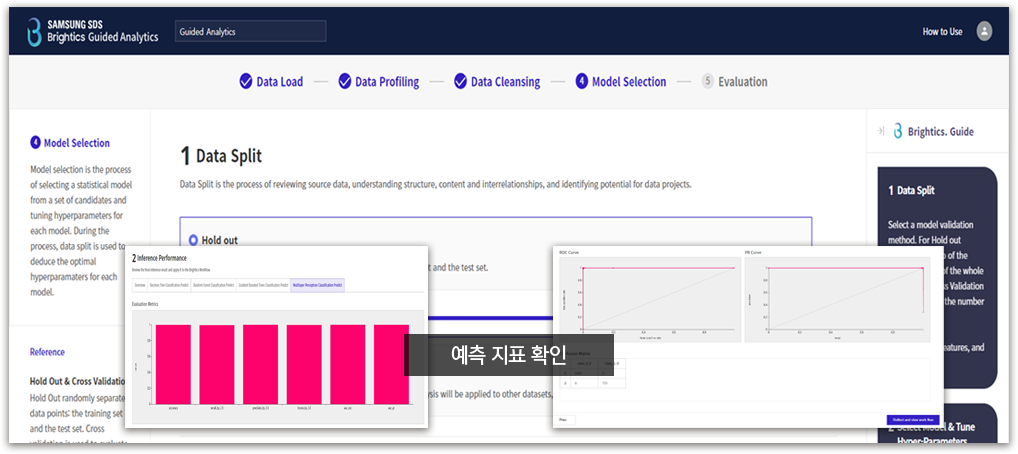
최적의 알고리즘 및 학습 인자, 딥러닝 모델을 자동 추천하고 분석 결과를 평가 기능 (4단계 분석 : Load→ Profiling → Cleansing → Model Selection → Evaluation) |
| Report 및 스케줄 관리 |
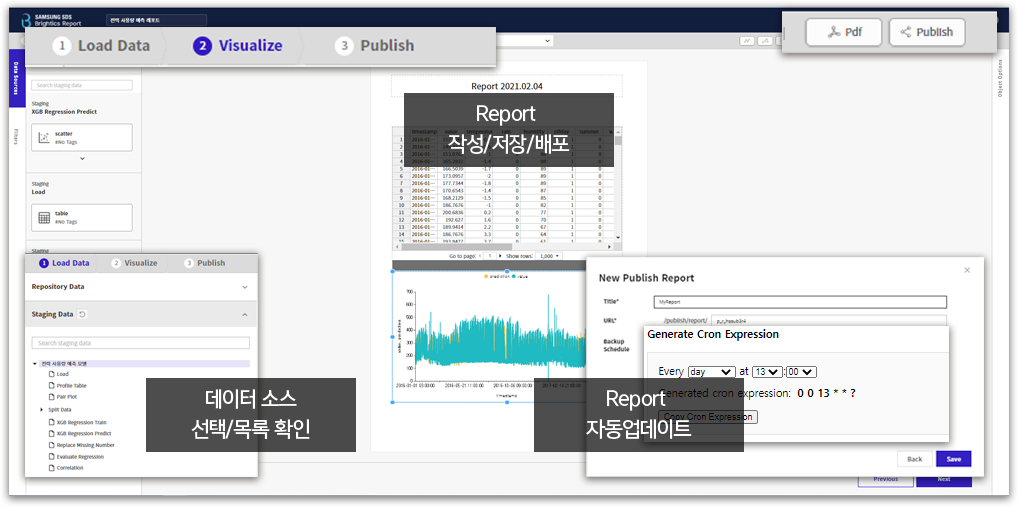
모델 분석결과를 Report화 하여 Report 관리 기능 제공하고 데이터와 Report를 스케줄러 기능으로 자동 업데이트 |
| 배포 관리 |
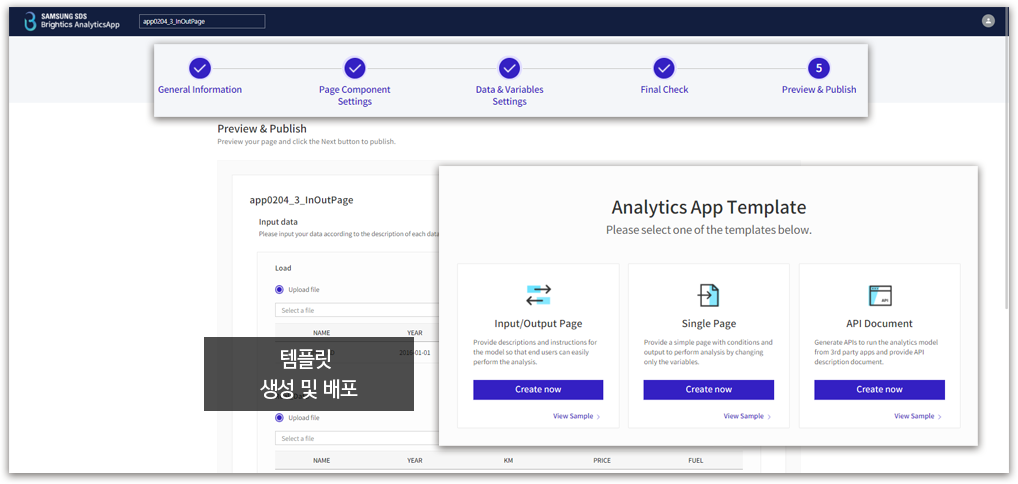
Analytics App을 통하여 분석 모델을 템플릿화 하여 배포할 수 있는 기능 |
eXperDB
데이터가 안전하고 효과적으로 관리될 수 있는
오픈소스 기반의 통합 데이터 플랫폼입니다.
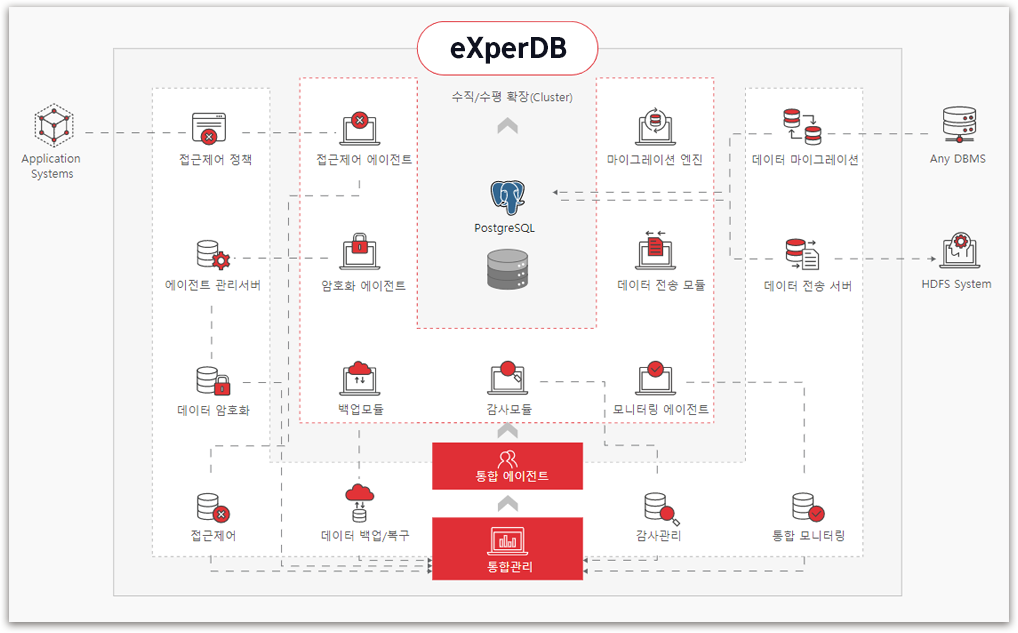
eXperDB 강점
DBMS 7총 마이그레이션 지원 및 GIS 데이터 완벽 전환
PostgreSQL 기반 높은 안정성과 다양한 기능성을 제공하는
오픈소스 DBMS 구축
신속하고 효율적인 부하 분산을 위한 클러스터 확장 가능
효율적인 데이터 Backup 및 안전한 Recovery 통합관리
빠른 이관 및 빠른 성능 보장
주요기능
통합 모니터링 기능
대용량 데이터 처리 · 공간 데이터 처리 기능
온라인 백업 및 복원 관리/데이터 암호화 기능
호스트 기반의 접근제어 관리 기능
사용자별/작업별 이력관리 등 데이터베이스 감사 기능
PostgreSQL → HDFS 실시간 전송 및 동기화 기능
Open BI
오픈 소스 기반의 안정된 Big data Analysis 환경으로
서비스 구축할 수 있습니다.
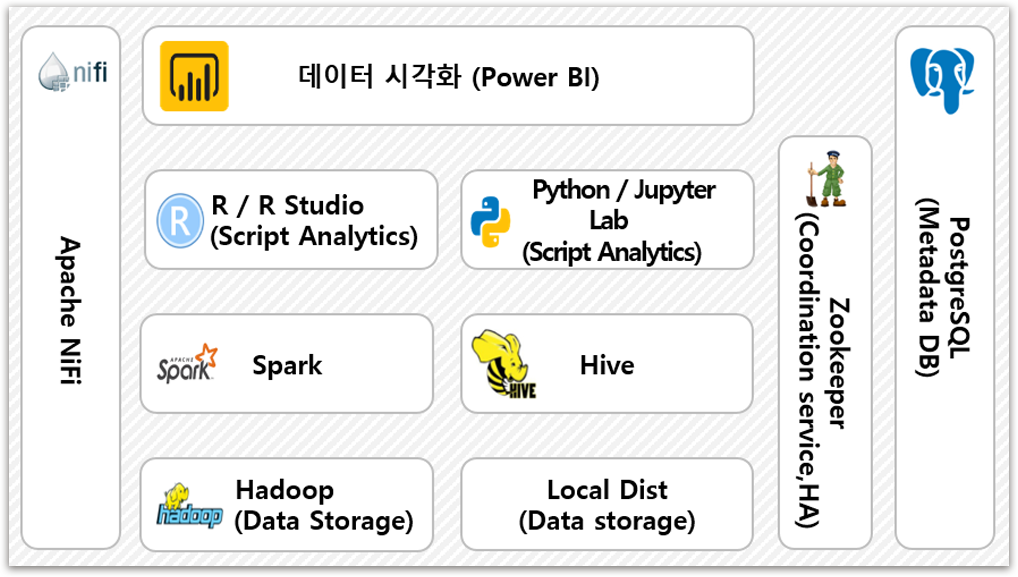
Open BI 강점
체계적인 오픈 소스 관리 기능 제공
데이터 분석 · 저장 기능을 활용한 효율적인 수집데이터 관리
대용량 데이터의 실시간 분석 및 빠른 처리 기능 제공
대용량 데이터를 체계적으로 관리하고 보호할 수 있는
보안관리에 유용한 데이터 플랫폼
주요기능
데이터 시각화 기능
데이터 분산 · 저장 기능
데이터 분석 · 데이터 분산처리 기능
하둡 데이터 조회 · 하둡 에코 관리 기능
데이터베이스 · 데이터 수집 · 전달 기능
모듈 서비스